Hi! This blog post will describe the AI application I have deployed, what it does and how to use it, and my experience with deploying the program. A demonstration of the application can also be viewed here: YouTube video.
Let’s take a look at the application:
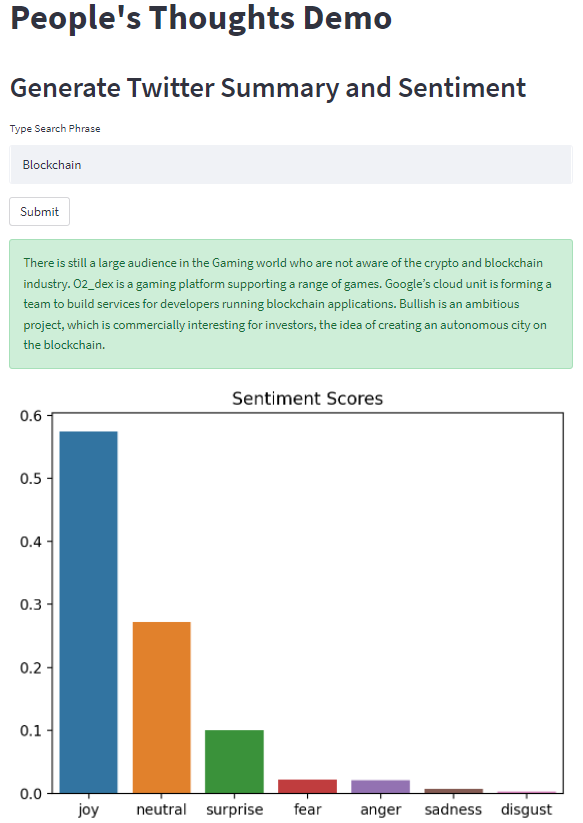
You can use this application by simply entering any search phrase into the search bar.
Within 10 seconds or less, you will receive a short summary of the most recent tweets related to the search phrase you entered along with a bar chart accurately classifying the sentiment of the collection of tweets.
In the case the application takes more than a few seconds, this may be due to your system not having a GPU. The model will then take just a few minutes to run.
Feel free to play with the application as much as you like and even use it periodically to catch up on the latest with things that interest you! I personally use it to get a feel for what’s going on with my favorite stocks.
Now let’s look at how this program was made…
Data Collection
The first step was to head over to Twitter’s Developer Platform to gain access to their API which would allow us to automatically pull tweets. Once granted API access, we used Twitter’s to find sample code for the Twitter API service we were using. To effectively query Twitter’s API, we studied their build-a-query guide
Model Selection
After collecting the necessary data, we chose our models for summarizing the tweets and classifying their sentiment. For this, we headed over to the infamous Hugging Face where you can find hundreds, if not thousands of pre-trained ready-to-use deep learning models mostly for natural language processing and computer vision tasks.
After trying a few models for the summarization task, I decided to go with this slauw87’s BART model for summarization . I chose this model because it was pre-trained on a dataset called SAMSum, which is made up of natural human conversations including slang words and informal texting patterns, which is what the data we wanted the model to generalize to, looked like.
As for the sentiment classifier, I wanted something more than just negative, positive, and neutral like most classifiers offer. Luckily, Jeff (member of the Ainize team) who had helped me several times with building this program had found and suggested j-hartmann’s distilROBERTA-base.
Data Processing
Before applying our two Hugging Face models, the data needed to be cleaned up. This meant formatting the data in a way that would allow the models to perform their best on the data. For this task, the data cleaning process consisted of removing duplicate tweets, ‘@mentions’, ‘$’ signs, ‘RT’ acronyms, website links, emojis, and non-English tweets. Removing emojis and non-English tweets were only necessary because our models did not support these types of data.
After this process, the data needed to be split up into groups less than or equal to the maximum text length that the summarization pipeline can handle. If interested, “Hierarchical Transformers for Long Document Classification” by Raghavendra Pappagari et al. offers an in-depth explanation regarding this limitation and the work-around method I used in this project.
In summary, the limitation is explained by this quote from the paper hyperlinked above:
[BERT suffers from major limitations in terms of handling long sequences. Firstly, the self-attention layer has a quadratic complexity O(n 2 ) in terms of the sequence length n. Secondly, BERT uses a learned positional embeddings scheme, which means that it won’t likely be able to generalize to positions beyond those seen in the training data.]
Summarization and Sentiment Classification
Now that we had collected the data, cleaned it, and prepared it for the models, it was time to apply our two Hugging Face models to the data. With a bit of research, insight from Jeff, and some trial and error, we came to ideal hyperparameters for the models that returned satisfactory results.
Parallel Computing and Docker
Our models by default use the CPU which is pretty slow to run. To solve this, we used Pytorch and Nvidia CUDA to enable GPU computing. In addition, our models needed to be pushed to Docker which they would later be pulled from. Unfortunately running a CUDA enabled process on Docker for Windows users is not a straightforward process and I recommend Jeff Heaton’s “Install WSL2 on Windows 11 with NVIDIA GPU and Docker Support” YouTube video for help getting started with this process.
Deploying the model
The last step of the project was to deploy this model using Flask, Ainize, and Streamlit.
First, we used Flask to pull in the search query, then we ran our pipeline on the query, and used Flask again to post the results back to an Ainize endpoint.
Once the results were posted to the Ainize endpoint, we used seaborn and matplotlib to create the sentiment bar chart, and the requests library with Streamlit to create a front-end user interface for interacting with the program.
Finally, our project was completed and anyone around the world with internet access could use it at their will.
Conclusion
In conclusion, given some prior experience using Docker, CUDA, and a backend API such as Flask; this method of web-interactive deployment is super convenient and straightforward. That being said, I learned quite a lot during the process and a stubborn desire to learn and conquer without prior experience will also allow you to deploy your model on the Ainize platform.
Special thanks to the AI Network at Common Computer, Jeff, and Changyeop.
That ends my blog post, please head over and try out my web-interactive application (linked at the top of this post) and feel free to offer any feedback you may have!
The code that went into developing this program can be found on my GitHub at /jonathanlampkin.
Citations
Pappagari, Raghavendra, et al. “Hierarchical transformers for long document classification.” 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) . IEEE, 2019
